Pour comprendre l’épigénétique, il faut déjà savoir ce qu’est la génétique. Chaque personne possède environ 70 milliards de cellules. Dans chaque cellule, il y a un noyau qui contient nos chromosomes. Nous avons 23 paires de chromosomes : 22 paires dites « autosomes » (communes aux hommes et aux femmes) et une paire sexuelle X-X pour les femmes, X-Y pour les hommes. Nos 23 paires de chromosomes sont composées par de l’ADN. Une fraction d’ADN est un gène. Nous comptons environ 25 000 gènes qui forment notre patrimoine génétique, unique à chacun. Les gènes indiquent à chaque cellule leur rôle dans l’organisme. A partir de l’information qu’ils contiennent, les gènes synthétisent des protéines indispensables à la vie : c’est la traduction du code génétique. Le fonctionnement de notre corps repose sur ces protéines. Quand le mode d’emploi de l’organisme comporte des erreurs qui provoquent une mauvaise synthèse des protéines, et donc des dysfonctionnements, c’est une maladie génétique héréditaire. Dans cet article nous allons revoir chaque étape de la transcription de ce patrimoine génétique et comment l’expression de nos gènes peut être influencée par notre environnement.
1ère partie la GENETIQUE
Le corps humain contient 50 à 70 milliards de cellules.
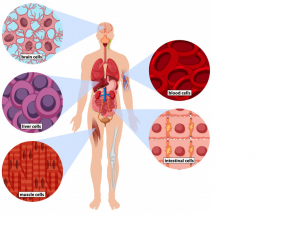
Chaque cellule contient des organites
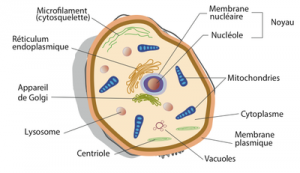
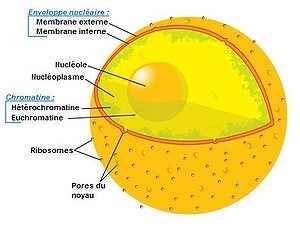
C’est dans le noyau que nous retrouvons nos chromosomes
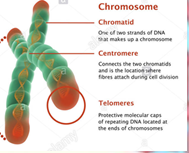

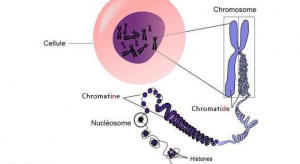
C’est en dépliant ces chromosomes comme une pelote de laine qu’on découvre les brins d’ADN
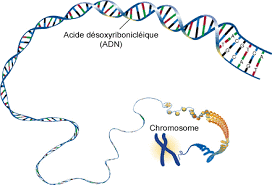
Pour savoir comment fonctionne l’ADN, nous allons rentrer un peu plus dans le vif du sujet en détaillants chaque phase.
1ère PHASE : la transcription par l’ADN polymérase (enzyme)
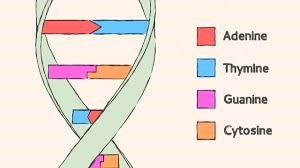
L’ADN est composé de 4 éléments chimiques qui constituent le code de notre patrimoine génétique. Ce code est composé des 4 éléments suivants : A (adénine), T (thymine), G (guanine), C (cytosine). Nous les appelons des nucléotides.
1. Initiation (promoteur) : L’ARN Polymérase reconnaît l’ADN et s’y fixe.
2. Elongation : L’ARN Polymérase avance et assemble des nucléotides pour transcrire un ARN pré-messager. Les T (thymines) sont remplacés par des U (uraciles). Il faut le voir comme une recette de cuisine qu’il faut recopier à la lettre près. Sur le brin non transcrit, vous avez des nucléotides que l’ARN pré-messager va recopier. Sur le schéma en rouge nous pouvons voir le message suivant : A, U, G, G, A, U, G, C, A, U, G, C. C’est ce message qui va être codé.
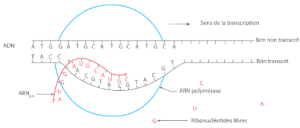
C’est à ce niveau-là que l’épigénétique va pouvoir faire son apparition.
Une fois que le message est transcrit, il y aura des exons qui sont des parties codantes séparées par des introns qui ont des parties non codantes.
On a toujours pensé que les introns étaient des gênes inutiles, muets ou des gênes poubelles. On s’est aperçu que ces introns avaient un rôle primordial dans l’expression de certains gênes. Je vous l’expliquerai dans la suite de l’article.

3. Terminaison : L’ARN Polymérase rencontre le site de terminaison et se détache de l’ADN
Ces 3 étapes vont permettre de créer un ARN Messager qui va subir une maturation.
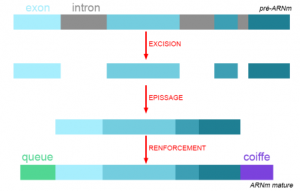
2ème PHASE : la maturation
Avant d’être envoyé dans le cytoplasme, l’ARN messager va subir une maturation.
1. Excision : retrait des parties non codantes (les introns) de l’ARN messager
2. Epissage : recollage des parties codantes (les exons) de l’ARN messager
3. Renforcement : renforcement des extrémités par une coiffe et une queue pour donner un ARN messager mature
3ème PHASE : Conversion
IL faut que les informations des nucléotides (A complémentaire U et C complémentaire à G) puissent être traduites en acides aminés. Pour comparer cela, c’est comme si un japonais essayait de communiquer avec un néerlandais, il faut un traducteur. Cet interprète s’appelle l’ARN T (ARN de transfert). L’ARN T va se lier sur les nucléotides et un autre va se lier à un acide aminé.
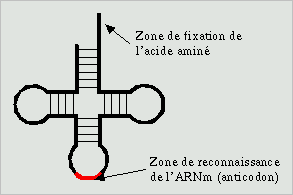
Le corps contient 20 acides aminés et l’ARN messager contient 4 nucléotides. Alors comment passer d’un langage à 4 lettres (A, U, G, C) à un langage de 20 lettres (acides aminés). Il faut que l’ARN T puisse lire plusieurs nucléotides et faire 20 combinaisons possibles.
Lire 1 nucléotide ne serait pas possible car ça nous donnerait que 4 possibilités :
4X1=4 combinaisons
A 1, U 2, C 3, G 4
Lire 2 nucléotides ne serait pas possible car ça nous donnerait que 16 possibilités :
4X4=16 combinaisons
AA, AU, AC, AG, UA, UU, UC, UG, CA, CU, CC, CG, GA, GU, GC, GG
Lire 3 nucléotides (CODONS) serait possible car ça nous donnerait 64 possibilités :
4X4X4=64 combinaisons
Pour pouvoir fabriquer les acides aminés, on aura besoin d’un code génétique
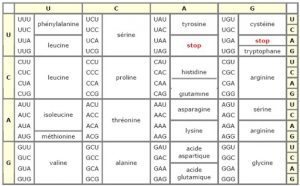
Prenons un exemple pour fabriquer un acide aminé. Ex : CGA comme codon
On va prendre la première lettre dans la colonne horizontale C
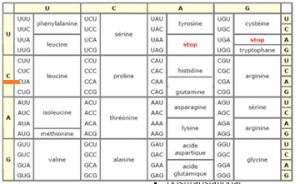
Ensuite, on prend la deuxième lettre à la verticale G
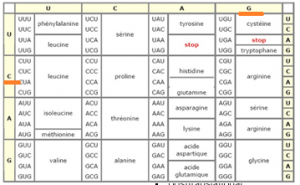
Finalement comme dans un jeu de « touché-coulé », on prendra la troisième lettre A en associant les deux premières lettres
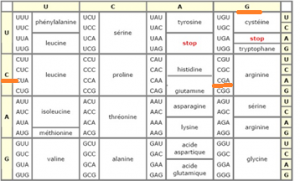
CGA= Arginine (acide aminé)
-Le codon AUG (méthionine) est le début de la traduction d’une protéine et le codon UAA ou UAG est la fin de la traduction
– Ce code génétique est universel : tous les êtres vivants traduisent les nucléotides de la même façon
4ème PHASE : la traduction
L’ARN M mature sort du noyau pour rejoindre le cytoplasme par un port nucléaire
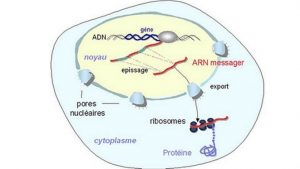
L’ARN messager arrive au niveau d’un ribosome dans le cytoplasme.
Un ribosome est une petite structure globuleuse qui est faite d’ARN ribosomale et de protéines.
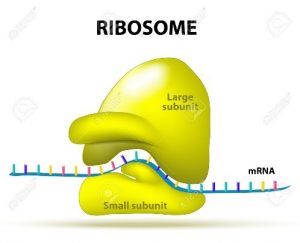
1.Initiation :
Pour démarrer la traduction, le ribosome doit commencer à partir d’un codon start AUG. L’ARN T va ensuite s’y disposer grâce à un code complémentaire de trois nucléotides (anticodon). L’initiation commence toujours par le code AUG qui correspond à la méthionine.
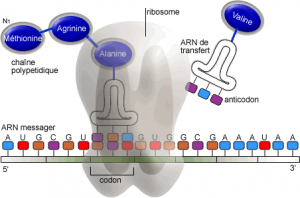
2.Elongation :
L’ARN M se déplace et le ribosome trouve le deuxième anticodon pour fabriquer un autre acide aminé (ex GUG= valine). Une fois accrochés, on parle de liaison peptidique.
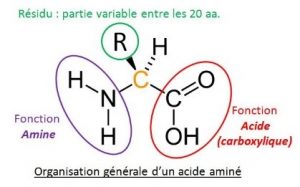
En biochimie un acide amine possède une fonction d’acide carboxylique (COOH) et une fonction amine (NH2).
Le ribosome permet la liaison peptidique. Il y aura d’autres ARN T pour créer une longue chaine d’acides aminés qu’on appelle un polypeptide.
3.Terminaison :
Dès que l’anticodon UAG ou UAA arrive au niveau du ribosome, c’est la fin de la traduction et le polypeptide se détache. La protéine n’est pas encore créée.
5éme PHASE : Le repliement
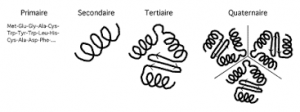
Pour que la protéine soit créée, elle doit avoir plusieurs structures en subissant des repliements.
Structure primaire : c’est uniquement le polypeptide qui sort du ribosome. C’est une structure simple qui ressemble à un long collier de perles.
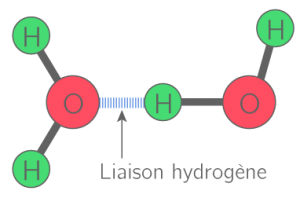
Structure secondaire : Certains acides aminés vont avoir de l’affinité entre eux. S’il y a affinité, les acides aminés vont se rapprocher pour créer une liaison temporaire. On appelle ça des ponts hydrogènes entre l’atome d’oxygène d’un acide aminé et l’atome d’hydrogène d’un autre acide aminé. Cela va provoquer des replis au niveau du polypeptide.
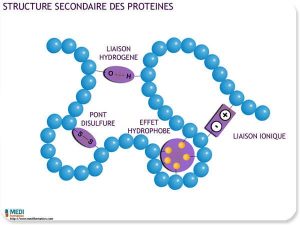
Cela va donner des formes en hélices (à droite) ou en feuillets (à gauche)

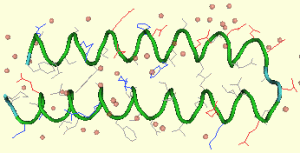
Structure tertiaire : Certains acides aminés vont être hydrophobes (qui repousse l’eau) et d’autres acides aminés vont être hydrophiles (qui aime l’eau). Grace à ces affinités les acides aminés vont se replier d’avantages.
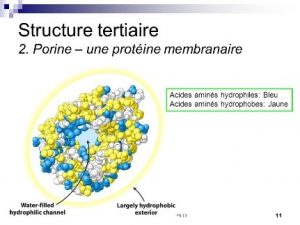
Structure quaternaire : Pour créer une protéine, il faut parfois assembler plusieurs polypeptides comme par exemple l’hémoglobine

En résumé
La protéine est créée pour produire son action importante de défense, de transport, de structure, de communication, de catalyse (enzymes), et de régulateur par l’épigénétique
2ème partie l’Epigénétique
On a vu dans la première partie, comment un gène permet de déterminer un caractère héréditaire en fonction du codant de la protéine. Quand le mode d’emploi de l’organisme comporte des erreurs et provoque une mauvaise synthèse des protéines avec des dysfonctionnements, on parle alors de maladie génétique héréditaire. On peut éviter ou retarder certaines de ces maladies, en fonction de ce que l’on va faire de notre environnement. La découverte récente appelée « épigénétique » est le fait de pouvoir contrôler l’expression de nos gènes soit en les allumant soit en les éteignant. Le code génétique ne change pas, mais la manière dont les gènes sont exprimés se modifie. Nous avons donc une influence sur nos gènes afin d’être en meilleure santé.
Quels sont les facteurs qui influencent l’expression de nos gènes ?
Notre corps est désigné pour vivre dans environnement naturel. Plus vous vous rapprochez de cet environnement naturel, plus vous changez l’expression de vos gènes en mettent en place :
– Une bonne alimentation : on sait l’importance d’une bonne alimentation pour notre santé. Il est très important de limiter les pesticides, les fongicides, les engrais, les colorants, les conservateurs, les additifs qui vont jouer un rôle néfaste sur nos gènes. Privilégiez une alimentation la plus brute possible, avec des légumes, des fruits, des bons acides gras et des aliments non raffinés.
– Des pensées positives : notre cerveau est un capteur d’informations et enregistre toutes nos émotions négatives. Plus nous ressentons de la colère, de l’injustice, de la peur, de la culpabilité plus vos gènes vont réagir face à ces informations néfastes. Cultivez plutôt la joie et le bonheur.
– De la méditation : Une pratique régulière de méditation à une action positive significative sur 61 sites de méthylation.
– Des bains de soleil : une exposition au soleil modéré permet de secréter de la vitamine D. La vitamine D permet une amélioration de l’expression de plus de 300 gènes.
– Du jeûne : le jeûne permet d’activer un gène le foxO qui va protéger l’ADN.
– Du sport : L’activité physique permet une amélioration de l’expression de plus de 600 gènes.
L’exposition au froid, au chaud et la respiration sont aussi bénéfiques pour notre santé.
Comment notre environnement influence nos gènes ?
Si vous donnez les bonnes briques de bases à votre environnement, le corps va sécréter des protéines régulatrices. Ces protéines régulatrices vont se fixer sur des récepteurs au niveau des cellules. Grace à ces récepteurs, la cellule va donner l’ordre aux gènes de s’exprimer au niveau de l’ADN. Une fois l’ARN messager transcrit, les introns vont pouvoir influencer la modification de nos gènes. Cela modifie nos gènes héréditaires et ceux de futures progénitures.
Ces introns vont permettre aux exons de changer en contrôlant leurs expressions. Ils vont pouvoir rajouter ou supprimer des exons. Ils vont également pouvoir bouger les exons d’un gène à l’autre pour modifier notre génome.
Ensuite le reste du message pourra être traduit afin de créer des acides aminés et des nouvelles protéines.

Quelles sont ces protéines régulatrices ?
Ce sont principalement les protéines kinases et des sirtuines qui vont influencer l’expression de nos gènes
Voici la liste des protéines régulatrices (liste non exhaustive)
– Les Sirtuines : il y a sept représentants nommés SIRT 1 à SIRT 7.
SIRT 1 : Elle est considérée comme un gène suppresseur de tumeurs. Elle a également des propriétés anti-inflammatoires et module le stress.
SIRT2 : Elle permet de protéger les lésions de l’ADN.
SIRT3 : Elle agit sur notre métabolisme et contribue à l’amélioration d’un syndrome métabolique.
SIRT4 : Elle permet l’expression des gènes dans les mitochondries des cellules du foie par oxydation des acides gras.
SIRT5 : son rôle est encore mal connu
SIRT6 : Elle intervient dans la réparation de l’ADN et dans la maintenance des télomères.
SIRT7 : Elle pourrait jouer sur le remodelage de la chromatine sous l’effet de l’ARN polymérase. Elle pourrait atténuer l’effet des lésions de l’ADN.
– L’AMPK : Elle agit sur le métabolisme notamment pour le diabète.
– PKG : Il a un rôle important dans la dégradation des protéines mal repliées.
– FoxO : Il protége notre Adn : C’est le gène de la longévité.
– HSP et CSP : elles ont un rôle de nettoyage et de restauration de la cellule.
– UCP1 a et PGC1 a , PPAR a: Ils agissent sur notre métabolisme en activant la thermogénèse (oxydation des acides gras)
Le PGC1a à un rôle sur la croissance neuronale (BDNF).
Cédric Schmidt Naturopate